
Optimising Code
This is about an unexpected but probably unavoidable, and hopefully somewhat interesting, distraction.
It’s too slow!
Back to working on software again. We had already built the beginnings of some sort of “framework” to have better foundations than we had last year, along with some of the high level control logic. It was all fine in simulation, running on a laptop: when “plugged in” to our little 2D robot simulator, the software worked great, processing (simulated) inputs, running some simple concurrent tasks, synchronising their outputs and driving a little rectangle around the screen.
But once we moved the code to a Raspberry Pi Zero and tried it for real in Phantom, there was a problem: it was all very slow.
One of the tasks (or “behaviours”) in our code is the one responsible for remote control: it picks up joystick input events and translates the (x,y) position of a stick to speed and turn angle. (These values are then used to drive the left and right motors.) It worked correctly, but it was sluggish, with a lag between joystick inputs and motor movements. With some debugging it became obvious that on the Pi Zero, our control code simply couldn’t keep up with all the input events coming in as the joystick moved. One iteration of the loop responsible for running “behaviours” and collecting the outputs of a few tasks took about 26 milliseconds to run. It may not sound much at first, but adding a delay like this can build up a large backlog of events so it can become noticeable – and this was the simplest possible job: no complicated calculations, just remote control!
Time to do some deeper investigation and measure what exactly takes so long and why…
Hy?!
First, a little background and some examples from our software:
Keeping up with the cutting edge of AI research from the 1950’s, we are experimenting with a Lisp dialect, called Hy: it transforms Lisp code to Python AST, so it’s all Python under the hood but with an arguably much nicer syntax plus other extra features, like macros. (Or you can also say that it combines the best of two worlds: the lightning fast speed of Python and the naturally easy readability of Lisp…)
In our high level controller code we have a function whose job is to merge a bunch of maps (dict objects) into a single one, while also dealing with some special cases.
The maps represent outputs from various concurrently running tasks, which we need to somehow merge into a single final output.
For example, let’s say we got these outputs from four tasks:
1
2
3
4
5
[{:speed 5 :dir 30}
{:msg "hello"}
{:battery-voltage 3.8}
None
{:speed 0 :dir 0 :msg "emergency stop"}]
The first one could come from our remote controller task: based on the joystick position, it is trying to drive at speed 5 and turn 30 degrees right. The second one is from something just emitting some log/debug message, the third one is reporting current battery voltage. The fourth one is just None: no output from this task, we just have to ignore it. Finally, the last one is from some sort of safety check, or maybe a reaction to a stop button being pressed: it’s trying to do an emergency stop.
We want to merge these into a single map like this, representing the final output:
1
[{:speed 0 :dir 0 :battery-voltage 3.8 :msgs ["hello" "emergency stop"]}]
The output from the last task (highest priority) overrides speed and direction. Messages are treated in a special way: when tasks output something under :msg, the values are all concatenated into a new list under :msgs. (So a higher priority task can override speed or any other output from a previous task in the list, but we want to collect all the messages.)
The initial implementation of this function to merge the maps looked like this:
1
2
3
4
5
6
7
8
(defn merge-outputs [outputs]
(defn merge [m e]
(setv [k v] e)
(if (= k :msg)
(append-to-msgs m v)
(assoc m k v))
m)
(reduce merge (chain #*(map (fn [d] (if d (.items d) [])) outputs)) {} ))
(append-to-msgs is another function that takes care of concatenating messages into a list under :msgs.)
The interesting bit is the last line. The Python equivalent of it would be:
1
reduce(merge, chain(*map(lambda d: d.items() if d else [], outputs)), {})
It is meant to be a nice example of doing the map-merge task in functional programming style, using itertools.chain to go through the list of all key-value pairs (while filtering out None outputs) from all the maps and building the final output using reduce.
Measurements
The above merge-outputs function is part of the code that was running unexpectedly slow. None of it was doing any complicated calculations or dealing with large amounts of data – it was only copying, comparing, deleting, moving things around from a few maps with a handful of items in them. Even if something there was horribly inefficient, it was hard to believe that it could make a huge difference.
Let’s experiment using the timeit module: measure exactly how fast this function runs on the Pi Zero, and try to improve it!
Here are the actual test results for the variations described below on the Pi Zero (times are in milliseconds for 100000 iterations):
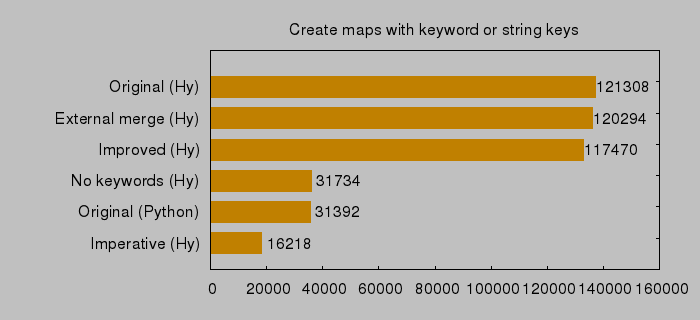
Original (Hy): The original function takes about 1.2 ms to run (with a very small amount of data). That is clearly too much!
External merge (Hy): merge-outputs has a small function, merge inside it. What if we move it outside, to the global scope? This makes it only very slightly faster, but doesn’t make any real difference.
Improved (Hy): It turns out that the last line can be done differently, using a list comprehension and chain.from_iterable: reduce(merge, chain.from_iterable([(dct.items() if dct else []) for dct in outputs]), {}) – a little bit faster, but still not much difference.
Original (Python): Converting the original function from Hy to Python made it almost four times faster! This was really unexpected: the Hy and Python versions should really generate the same bytecode at the end, using the same Python standard libraries, etc. There is one difference though: keywords don’t exist in Python. So when testing the Python version of the function, we used string keys.
No keywords (Hy): Following the above: let’s keep the original Hy source, but replace keywords with plain strings: almost exactly the same speed as the Python version. That makes sense, so Hy is not really worse than Python – but why are strings faster? Let’s put this aside for now and try to optimise further…
Imperative (Hy): What if we forget about all the elegant functional tools we used, and rewrite the whole thing in more verbose, imperative style with a for loop, a bunch of if statements and using dict.update in the loop? Noticeably faster than the previous attempt – at 0.16 ms, 7.4 times faster than the original, this is clearly the winner!
1
2
3
4
5
6
7
8
9
10
11
12
(defn merge-outputs-hy-no-kw-imperative [outputs]
(setv ret {})
(for [output outputs]
(if output
(do (setv msg (.get output "msg"))
(if msg
(append-to-msgs-no-kw ret msg))
(.update ret output))))
(if (in "msg" ret)
(del (get ret "msg")))
ret)
We talked about how the problem wasn’t even noticeable in simulation, when running on a laptop. So how much slower is the Pi Zero really? Comparing it with a (not exactly new or super fast) ThinkPad T430 (Intel i5) laptop:
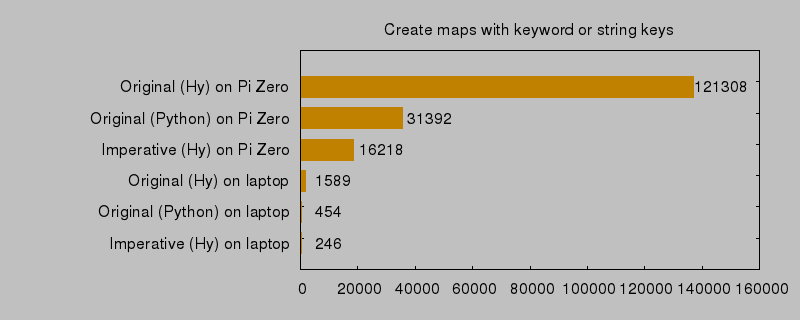
The laptop is about 60–70 times faster in these tests. Even the worst version is ten times faster on the laptop than the best one on the Pi Zero!
Now let’s have a look at why using keywords for map keys is slower than strings. In Python you can use any object as a key in a dict, provided you implement the required methods correctly. In Hy, keywords are implemented as a HyKeyword class, which is just a very simple wrapper around a string value. So far it all sounds reasonable: we might expect a little more overhead, but not much. But what actually happens when you create a map with keyword literals as keys?
{:foo 1 :bar 2} in Hy is translated to {HyKeyword('foo'): 1, HyKeyword('bar'): 2}. Compare this with {"foo": 1, "bar:", 2}: with keywords, we’re creating new instances of the HyKeyword class every time we specify a key! The same thing happens when accessing a value: (:foo mymap) becomes mymap.get(HyKeyword("foo")). And of course this explains why there is a big difference, as we can see below.
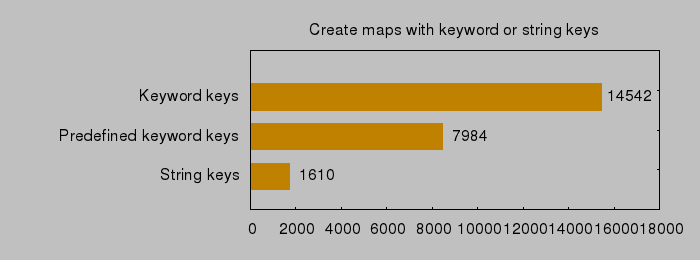
Creating maps with keywords and strings – and trying to improve keywords by defining them first as “constants” before using them in maps:
Similarly, for accessing values by keys:
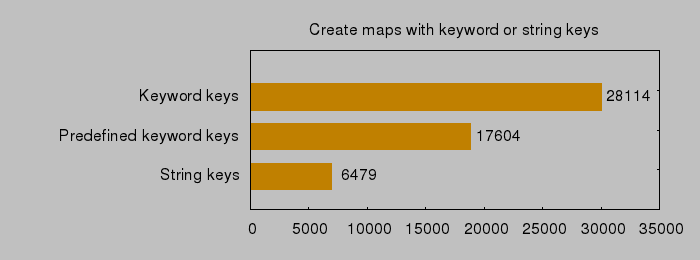
So it looks like no matter what we do, strings are really the best. The overhead of using an object wrapper is quite large.
The performance tests shown above can be found in our python_perf_tests repo on GitLab.
All the above is just half of the whole story. A lot more changes had to be made to the code to finally make everything run at an acceptable speed, mainly:
- Instead of many small functions that clearly focus on doing only one thing, merge the logic into a few bigger functions that do “everything” in one go, blurring responsibilities (to avoid extra iterations or having to carry around intermediate data between functions).
- Stop making functions pure: instead, share the same mutable state across functions (to avoid creating and discarding lots of objects all the time).
This of course doesn’t sound like good practice at all – unless you are optimising for speed.
Just as a quick example, for a relatively simple function that updates some values in a map following some rules and either returns the result as a new map or mutates the original:

There is another important idea that was missing from our initial “naive” joystick code: sometimes you can’t control the rate of your inputs (joystick or measurements from sensors, etc.) and they come in faster than you can process. In this case, instead of building a backlog (queue) and trying to process everything eventually, it’s better to just discard everything but the last event and process only that: it makes no sense to carefully go through the last 10 distance measurements or all the detailed movements of the joystick from the last few seconds or even milliseconds: all you need is the value right now – it’s too late to worry about what happened before. (This isn’t always the case however: sometimes you do need to look at everything if you want to detect changes in a series of values to recognise something.)
Summary
The overall price for fixing our problem was really a lot of time spent on testing and optimising, and as an end result, less clean code: it’s harder to understand, does some dangerous things, and in general is less “correct”.
There is rarely such a clear choice between fixing something in software or hardware, with obvious tradeoffs as here:
Option one: Just use more powerful hardware so that the problem goes away even if the software is inefficient: a more powerful Pi would be an obvious choice here. But that means a bigger footprint (which might need changes to the robot body / layout), more power, so maybe bigger batteries, which leads to more weight…
Option two: Optimise the software to make it work with the given hardware: this means a lot of time spent on testing and rewriting code, and possibly having to give up some “nice things”, making the code more efficient but less safe and/or maintainable. We have to give up some of our ideals or tools. Or we might even need to look for something faster than Python!
Finally, some very obvious conclusions:
- The Pi Zero is slow.
- Python isn’t lightning fast either.
- Python isn’t the the best choice for functional programming with immutability.
- If you have a small part that is slightly slow but you use it all the time, it can make the whole thing very slow.
- Early optimisation may be the root of all evil, but if you leave it too late, it might cause some headaches.